본 게시물은 러닝 스푼즈의 '내 서비스에 딱맞는 AI 에이전트 만들기 : RAG, LangGraph, LLM 파인튜닝' 현장 강의를 듣고 요약 및 재구성한 게시물임을 알려드립니다.
- 강의 관련 url : https://learningspoons.com/course/detail/ai-agent-master/
내 서비스에 딱맞는 AI 에이전트 만들기 : RAG, LangGraph, LLM 파인튜닝
나에게 딱 맞는 AI 에이전트를 구현하고 싶다면? 대기업에서 LLM 파인튜닝으로 에이전트 개발을 하고 있는 연구원의 실무 노하우가 가득 담긴 강의!
learningspoons.com
본 강의에서 다룰 키워드
- RAG 개요
- 임베딩과 검색기
- GPT-4 사용을 위한 API Key 발급
- Lanchain
- Chunking
- Retriever
- 멀티턴과 멀티 쿼리
- Function Calling
- Fine-tuning for RAG
# 1. RAG(Retrieval-Augmented Generation)
1. RAG 개요
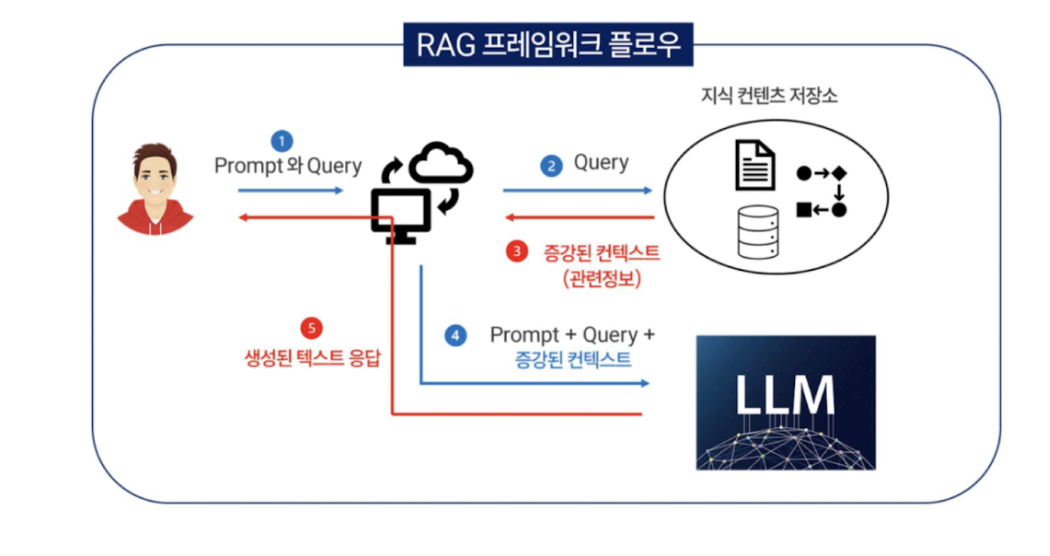
RAG : 검색으로 증강된 답변을 생성한다. 즉, LLM의 지식에 외부의 지식을 추가하여 답변하는 것
- R(Retrieval) : 검색 / A(Augmented) : 증강되었다 / G(Generation) : 생성한다.
- RAG에서는 사용자가 질문을 던지면 질문과 연관되어져 있는 문서들을 찾아낸다. (검색기가 존재)
- 검색기가 문서들을 찾아내면 해당 문서들을 바탕으로 LLM에게 답변을 요구
- 이 경우, LLM은 검색된 문서들을 바탕으로 질문에 대해 답변하므로 기학습 지식이 아닌 외부지식을 바탕으로 답변
- 참고자료 : https://www.slideshare.net/slideshow/2024-05-01-rag-rag/269542352#4
2024.05.01 RAG 세미나: 자연어처리의 정보검색 기법과 최신 RAG 모델
자연어처리의 정보검색 기법과 최신 RAG 모델 - Download as a PDF, PPTX or view online for free
www.slideshare.net
2. LLM의 과금 구조
LLM은 크게 API 형태와 다운로드하여 쓰는 오픈 모델 형태 두 가지로 사용한다.
① API : 사용한 만큼 돈을 지불하는 유료 모델. 실제로 모델을 다운로드 할 수는 없음. 단, GPU가 필요 없음. 토큰당 과금
② 오픈 모델 : Huggingface에서 모델을 다운로드하여 사용하는 모델로, 실제로 모델을 다운로드해서 사용. 하지만 LLM을 가용하기 위해서는 GPU가 필요
✅ 토큰 : LLM이 입력된 텍스트를 분리하여 인식하는 단위로, 일반적으로 사람이 인식하는 단어 단위랑 비슷하면서 좀 다름
3. OpenAI의 토크나이저
토크나이저 : 언어모델이 텍스트를 분할하기 위해 사용하는 도구/방식을 의미
- 언어모델마다 동일한 텍스트라도 토큰 분리 방식 및 효율이 다름
동일한 텍스트에 대해서 더 적은양의 토큰으로 분할되는 것이 중요한데, 이에 대한 이유는 아래와 같음
① 언어모델의 생성속도에 영향을 미친다.(언어 모델은 토큰을 1개씩 생성하면서 글을 완성한다.)
② 일반적으로 사용한 토큰만큼 과금이 되는 구조
동일 텍스트 입력에 대해 토큰 효율 및 비용을 따져본다면 GPT4o와 CLOVA-X를 비교해본다면 CLOVA-X가 더 좋음
- 단, OpenAI는 영어 데이터를 훨씬 더 많이 학습하여 영어의 경우 한글보다 더 비용 효율적임 (Byte Pair Encoding 방식)
- 따라서 많은 호출을 요하는 경우, 프롬프트를 영어로 작성하는 것이 과금 절약에 도움이 된다.
- 프롬프트는 영어로 하되 맨 마지막에 한글로 답변해달라고 적으면 답변은 한글로 나온다.
4. LLM API 가격 정리
- Open AI외에도 많은 LLM들이 전부 토큰당 과금 방식을 사용
- https://llm-price.com/#google_vignette
# 2. 임베딩과 검색기
1. 임베딩(Embedding)과 임베딩 모델
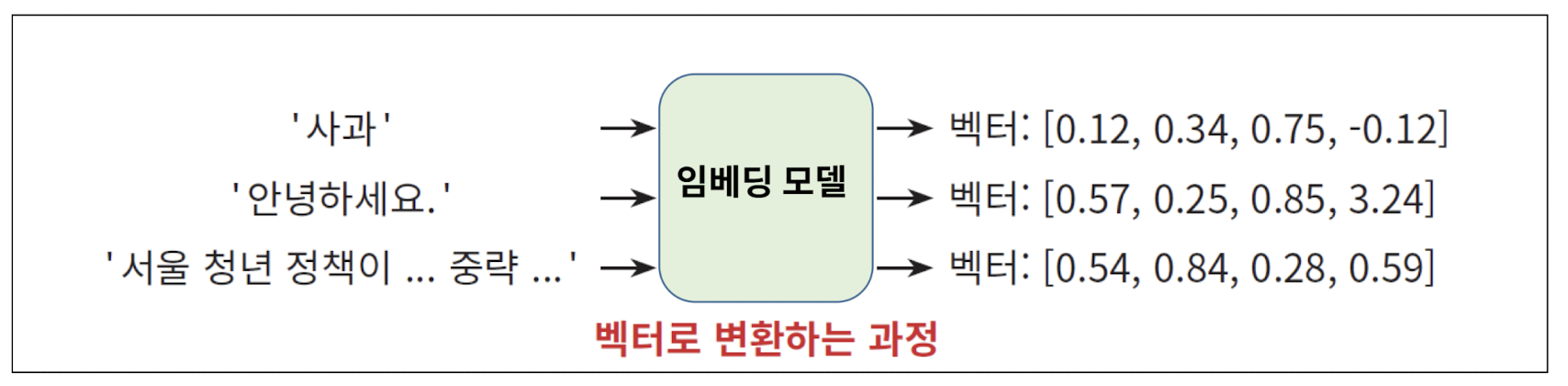
임베딩 : 텍스트를 AI를 이용해 숫자 특히 벡터로 변환하는 것
- 임베딩 모델은 직접 공개된 모델을 다운로드하여 사용하는 것과 API로 제공받는 것 총 두 가지
- 공개된 모델을 다운로드하여 사용하는 경우 '보안', '직접 도메인에 맞게 학습하여 성능 최적화' 등 이유가 존재
- OpenAI에서 제공하는 유료 임베딩 api들도 있고, 기본 성능은 보장되며 유료임. 사용자 데이터로 추가 학습은 불가능(25년 7월 기준)
2. 유사도 : 임베딩을 하는 이유
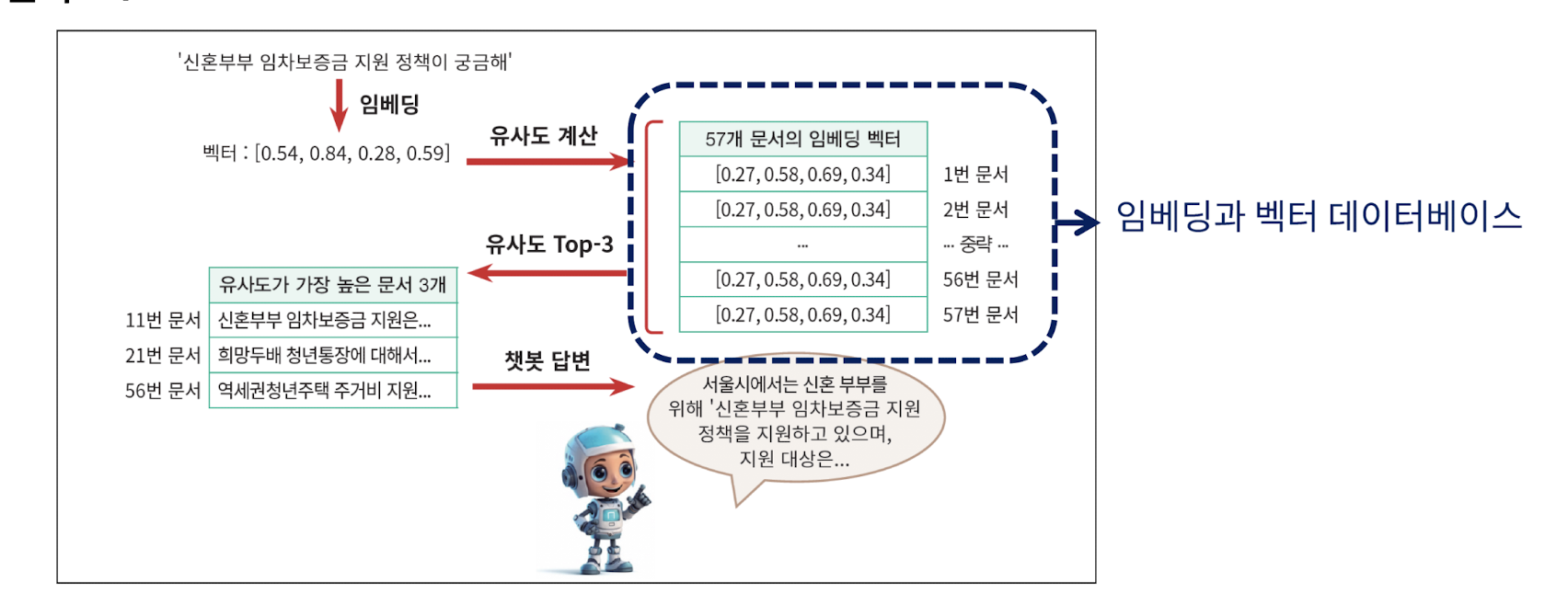
- 텍스트를 임베딩하고나면 텍스트끼리의 유사도를 구하는 것이 가능하다. 즉, '검색기'를 만들 수 있음
- 대표적으로 코사인 유사도가 존재

- 즉, RAG 구축 시 벡터DB의 정보들과 질의를 비교하는 검색기가 존재하는데, 이 검색결과를 바탕으로 LLM에게 질문에 대한 답변을 요구한다. 이 때 검색된 내용을 바탕으로 '답변'하므로 내 데이터만을 이용하여 답변하는 챗봇 구현이 가능하다. 이로써 챗봇이 거짓말하는 현상인 '할루시네이션'을 급감시킬 수 있는 효과가 있다.
- 임베딩을 이용하여 검색기를 구현한다는 것은 기존 문서들의 임베딩을 보관할 장소가 필요하다는 것
3. 임베딩 실습
임베딩은 크게 API형태와 다운로드하여 쓰는 오픈 모델 형태 두 가지로 사용한다.
- API : 사용한 만큼 돈을 지불하는 유료 모델. 실제로 모델을 다운로드 할 수는 없음
- 오픈 모델 : Huggingface에서 모델을 다운로드하여 사용하는 모델. 실제로 모델을 다운로드해서 사용(무료)
4. Vector Database
- 벡터 데이터베이스는 벡터를 저장하는 장소로, 벡터를 저장/관리/검색(유사성 기반)하는 일
- 코사인 유사도와 같은 유사성 검색을 기반으로 상위 N개의 벡터를 반환한다.
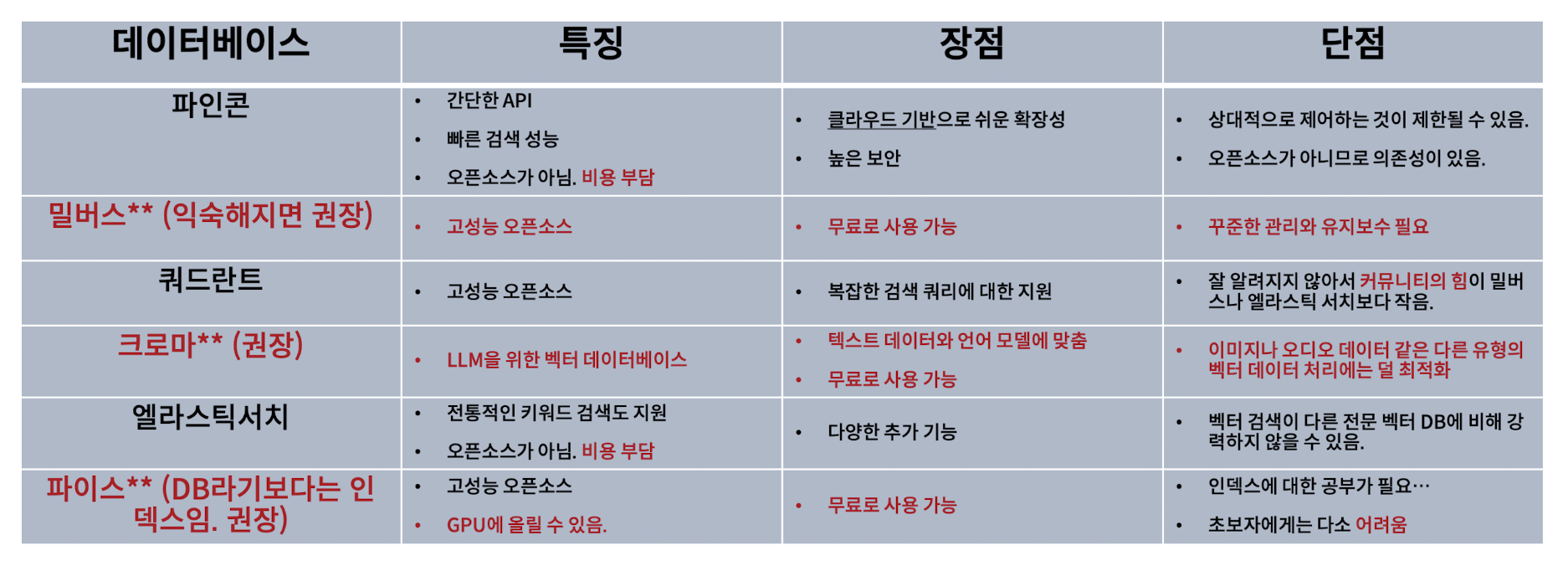
- 밀버스는 에러가 많고, 크로마는 현업에서는 잘 안씀
- 현업에서 많이 쓰는 벡터DB는 밀버스, 쿼드란트, 파이스
# 3. Langchain을 넘어서
1. LangChain
- RAG에서 LangChain이 필수는 아님.
- Langchain을 사용하면 많은 코드를 간소화시켜주고, 실제로 크 회사에서 rag 프로젝트를 수행하는 경우에는 앞으로의 유지보수가 중요성이 크므로 LangChain을 배제하기도 하지만 LLM과 RAG를 처음 접하는 사람들에게는 좋음
- 다만 RAG를 더 깊이 이해하기위해 더 높은 난이도의 RAG 프로젝트를 수행하고자 하는 분들은 LLM과 RAG 그 자체의 본질에 대해서 공부해야함
① 테이블, 표 가득한 헬 난이도의 pdf 문서의 전처리는 LangChain 만으로는 절대 안됨
② 보안 상의 이유로 GPT-4가 아니라 LLaMA와 같은 다운로드형 오픈 모델을 사용하는 경우
: 파인튜닝을 하면 RAG 성능을 상당 부분 up 가능하지만, Langchian과 파인 튜닝은 연관 관계가 없으므로 별도 공부가 필요함
- 직접 파인튜닝이 어렵다면 오직 프롬프트 엔지니어링만으로 RAG를 해야함.
- 파인튜닝 학습 가격은 생각보다 비싸지 않으며, 파인튜닝 전/후 모델의 유지 비용이 어차피 같다는 점에서 파인튜닝은 무조건 학습할 필요가 있음
③ 각종 LLM들이 연결된 에이전트 RAG
- Langchian에서 기본 세팅된 프롬프트들은 보통 성의가 없어서 직접 작성하는 경우가 많은데, 이에 에이전트 자체에 대한 이해도가 필요
- 재시도, 도구 선택 등 각종 에이전트형 RAG에는 다양한 모델들을 직접 파인튜닝 하는 경우 파인튜닝 능력이 필요
- 에이전트 엔진의 커스텀 영역으로 들어가게 되면 이때부터는 에이전트 지식이 있는 백엔드 엔지니어의 role (즉, 자체 개발 역량 필요)
2. ChatGPT API vs LangChain
- Langchain은 필수가 아니기에 Langchain 코드의 대부분은 대체 코드가 존재함
- Langchain은 다양한 API의 사용 방법을 Langchain 특유의 문법으로 통일시킨 것이 특징
- Langchian으로만 LLM을 가볍게 접한 사람들은 심지어 'role'의 개념을 모르는 경우가 많음

3. ChatGPT API의 프롬프트 입력 형식
사용자의 질문 프롬프트가 user role로서 입력이 되고, chat GPT의 답변이 assistant로서 누적되어 과거의 대화 내역을 누적시켜서 다음 답변 요청이 가능
① System
- LLM에게 시키고자 하는 역할을 명확히 지시하는 구간
- 일반적으로 system 프롬프트는 고정되어져 있음 (가변 사용도 가능)
② User : 사용자가 질문을 하는 구간
③ Assistant : 챗봇의 답변
4. Temperature와 max_token
추가적으로 temperature와 max_tokens 파라미터를 사용하는 것이 가능함
- temperature : 높으면 답변의 랜덤성을 높임. 답변이 매우 전형적이기를 바란다면 값을 0을 주면 되지만, 답변의 랜덤성을 높이고 싶다면 값을 높이면 됨. 값이 높은 경우에는 거짓도 섞일 가능성이 높아짐
- max_tokens : 답변의 최대 길이를 제한함. 길이가 지나치게 짧으면 답변을 중간에 잘리게 만듦
5. LangChain 문법은 빠르게 변화하고 커스텀이 필요
- LLM과 기존 API에 대한 이해 없이 랭체인만 공부 X
- LLM과 랭체인이 랩핑하고 있는 오리지널 API나 에이전트의 오리지널 논문을 공부해야 랭체인이 업데이트 되거나, 커스텀이 어려운 상황일 때 빠르게 대처하여 구현하는 것이 가능함
# 4. Chunking
1. LangChain의 대표적인 기능 : Chunker
1-1) Chunking의 개념
- 하나의 긴 문서가 있을 때 이를 RAG로 구현하기 위해서는 긴 문서를 작은 문서들로 분할하는 작업을 청킹(Chunking)이라고 한다.
- 청킹 후에 이 분할된 각각의 문서들이 임베딩이 되어 벡터DB에 적재된다.

1-2) 랭체인에서 제공하는 대표적인 Chunker
① RecursiveCharacterTextSplitter
- 길이 단위로 자른다. 따라서 문맥이 중간에 잘리는 구간이 발생할 수 있음
- 이에 따라서 자를 때 내용이 겹치도록 하는 chunk_overlap을 지원하나 임시 방편 수준
② SemanticChunker
- 임베딩 모델을(ex.openAI의 임베딩 API 등) 이용하여 문맥별로 자른다.
- 문맥별로 자르면 이상적으로는 좋은 성능을 얻을 수 있지만, SemanticCunker 성능 자체는 애매함
2. LangChian의 Chunker를 넘어서
Chunker는 빅테크사에서 따로 1개씩 구현하고 있는 경우가 많을 만큼 중요한 모델임. (Lanchain에 있는 것만 써서는 안됨)
ex. NCP서는 문단 나누기 모델을 별도 학습한 것을 API 형태로 제공함
3. 고급 Chunking - 랭체인에 매몰되지 말자
Chunker의 종류
① LLM Based Chunker (프롬프트 엔지니어링...)
- 사람이 자르는 것과 비슷한 효과를 내기 위해 LLM 자체를 Chunking에 활용하는 전략
- 좋은 성능의 LLM(ex GPT 40)과 같은 모델과 프롬프트 엔지니어링으로 구현 가능
② PLM Based Chunker (Fine-tuning)
- NLP 엔지니어라면 T5와 같은 모델로부터 이어지는 두 개의 문장 내지는 문단을 주고 판단하도록 학습한 후, 일종의 임계값으로 조절하면 꽤 뛰어난 Chunker로 동작함. Langchain의 기본 Semantic Chunker의 정교한 커스텀 버전
③ 합성 데이터 방식
- 주어진 문서로부터 새로운 문서를 만들어 이를 벡터DB에 적재하는 전략
- QA 방식, 앤트로픽의 Context Retrieval 방식, PAPTOR 방식 등...
- 잘 사용하면 굉장히 강력함. 몇 가지 테크닉을 사용하면 장기 의존성 문제 해결 가능 (GraphRAG 이상의 성능도...)
(합성 데이터 QA 방식 예시)
- 복잡한 문서를 아래와 같은 다수의 데이터로 재작성하고 이 데이터를 애초에 검색 문서로 지정

4. 멀티모달 RAG : 랭체인 외에 여러가지 방법을 동원
- 테이블, 이미지가 존재하는 복잡한 데이터를 임베딩하고 RAG를 수행하려면, 셀병합이 있는 복잡한 테이블을 전처리 하여 최고 성능으로 답변하려면 Unstructured.io 및 VLM(Claude, Qwen2-VL 등)로 진행 : 추후 상술
# 5. Retriever
1. Langchain의 벡터 데이터베이스
- 랭체인은 서로 다른 파이썬 도구들의 사용법을 통일시켜줌
- 예를 들어 가장 보편적인 벡터 DB인 Chroma와 Faiss의 통일된 코드는 아래와 같음

2. 키워드 기반의 검색
- 임베딩 기반의 검색에만 의존할 필요는 없음
- 기존의 검색 엔진에서 사용하고 있는 키워드 기반의 검색(BM 25)을 함께 사용하는 것도 좋은 전략이다.

3. 검색 성능 향상 기법들
3-1) Reranking : 두 번의 검색으로 검색 성능 향상
- Reranking : 검색을 두 번 수행하여 검색 성능을 높이는 방법. 두번째 모델은 '크로스 인코더'를 사용
- 첫번째 임베딩 모델로 검색을 하고 후보를 추린 후에 두번째 모델로 순위 조정을 한다.
- 두 개의 임베딩 모델을 '내 데이터로 추가 학습'한다면? 최고 검색 성능 달성

3-2) HyDE : 질문에 대한 답변으로 검색해서 검색 성능 향상
- HyDE : LLM이 사용자의 질문에 대해서 임의로 '답변'을 하고 그 '답변'으로 검색을 하도록 하는 방법
- 질문과 답변의 유사도가 아니라 답변과 답변의 유사도를 구하므로 검색 성능을 올릴 수 있음
- 구현 방법도 쉬움

3-3) 임베딩 파인튜닝 : 추가학습을 통해서 검색 성능 향상
- Reranking까지 사용한다면 두 개의 임베딩 모델을 전부 추가 학습하여 내 데이터 최적화 가능
- 파인 튜닝이라는 용어로 부르는 추가 학습의 개념을 위해서는 몇 가지 노하우가 필요

# 6. 멀티턴과 멀티 쿼리 대응하기
1. 멀티턴 해결하기
1-1) 멀티턴이란?
- 멀티턴 : 이어지는 대화에서 이전 대화를 반영하여 검색을 수행하도록 하는 것을 의미한다.
1-2) 멀티턴 해결하기
- 멀티턴 RAG를 구현하는 방법은 여러가지가 있지만 (ReACT Agent, 별도의 이전 대화 반영 모델 등) 기본적으로는 이전 대화를 누적 입력으로 사용하여 검색어를 정제하도록 하는 것
- 아래 예시에서는 이전 대화를 반영하여 검색어를 생성하는 별도의 모델을 보여줌 (GPT-4 or Qwen 튜닝 등)
- 이 과정을 항상 검색하기 전에 수행하도록 파이프라인을 구성하면 멀티턴 수행이 가능
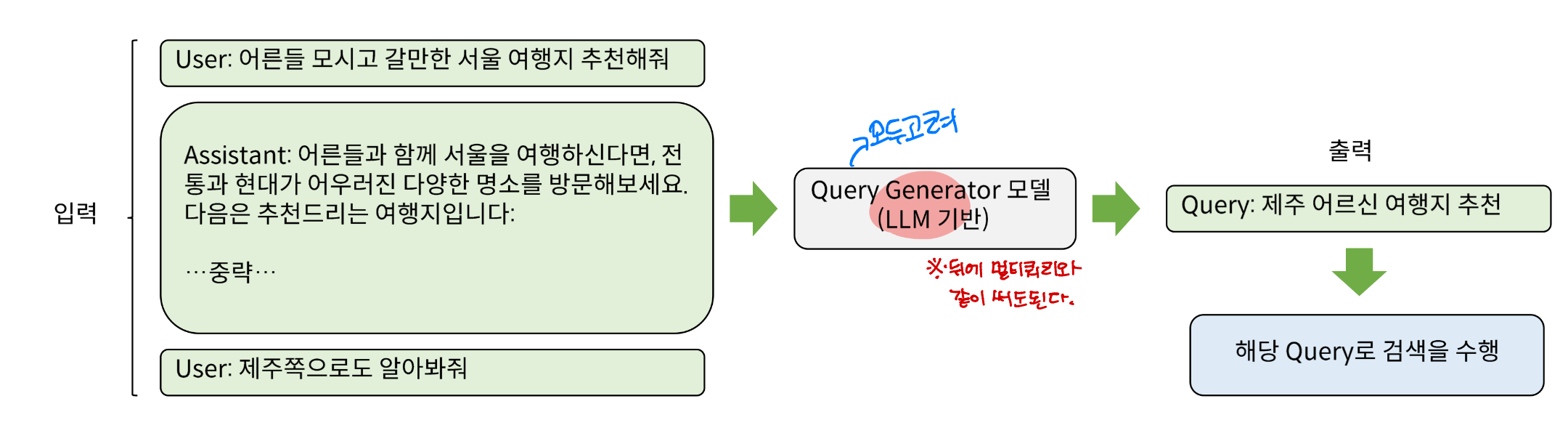
2. 멀티 쿼리 해결하기
2-1) 멀티 쿼리란?
- 멀티 쿼리 : 'A와 B와 C를 알려줘'를 동시에 알려달라고 했을 때 이를 적절하게 쿼리를 분리하여 수행하는 능력을 의미
2-2) 멀티 쿼리 해결하기
- 멀티 쿼리 또한 멀티턴과 마찬가지로 별도의 모델을 두는 것이 가능 (설계에 따라서는 멀티턴과 멀티쿼리를 동시에 수행하는 모델을 개발하는 것도 가능)

3. ReACT 에이전트 : 멀티턴, 멀티 쿼리 해결 가능 (참고)
기존의 유명한 생각하는 에이전트 방식에 약간의 프롬프트 엔지니어링을 사용하여 이를 해결하는 것도 가능
예를 들어 ReACT 에이전트를 사용하면 모델이 스스로 쿼리를 분리하여 검색을 순차적으로 실행 후에 취합

# 7. 외부의 도구를 사용하는 방법
1. Function Calling
- Function Calling : 대화를 하다가 함수를 호출하는 방법

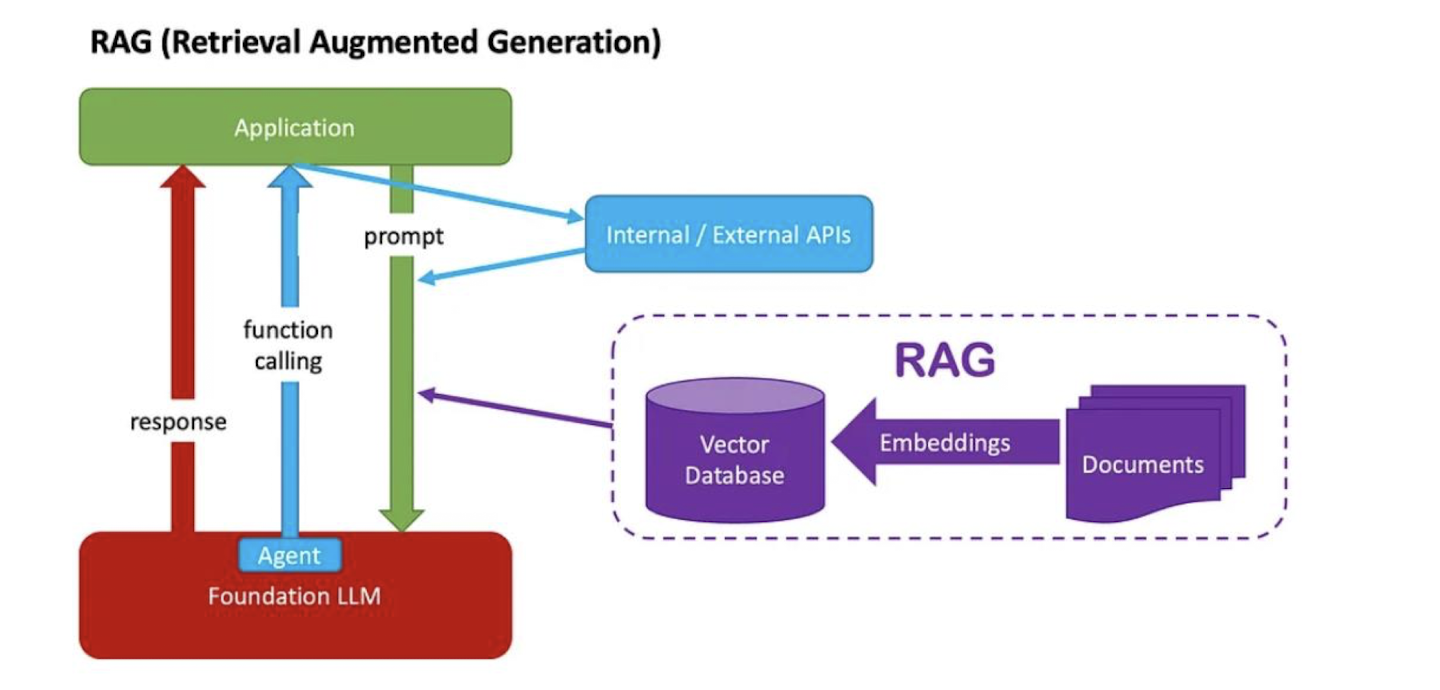
2. 에이전트 RAG

