- 엑셀의 필터처럼 데이터프레임내에서 특정 조건을 만족하는 데이터만 필터링을 할 수 있는 조건필터 기능과, 컬럼별 결측치를 확인하는 기능, 값을 변경하는 기능을 알아본다.
- 실습환경 : colab
실습에 필요한 데이터프레임 생성하기
import pandas as pd
import numpy as np
data = {
"메뉴":['아메리카노','카페라떼','카페모카', '바닐라라떼', '녹차', '초코라떼', '바닐라콜드브루'],
"가격":[4100, 4600, 4600, 5100, 4100, 5000, 5100],
"할인율":[0.5, 0.1, 0.2, 0.3, 0, 0, 0],
"칼로리":[10, 180, 420, 320, 20, 500, 400],
"원두":['콜롬비아', np.NaN, '과테말라', np.NaN, '한국', '콜롬비아', np.NaN],
"이벤트가":[1900, 2300, np.NaN, 2600, np.NaN, 3000, 3200],
}
df = pd.DataFrame(data)
df

#1 조건 필터
- 기본적으로 df[조건]의 형태를 띄고 여기서 조건은 'df['col_name'] > 숫자'의 형태이다.
> 1개 조건
# 할인율 > 0.2
df[df['할인율'] > 0.2]

(또 다른 표현)
# 할인율 > 0.2
cond = df['할인율'] > 0.2
df[cond]
- 이런 식으로 조건 식을 따로 써주는 방식은 조건필터에서 전체적으로 통용되는 방식이다.
> 2개 이상 일때 (AND)
- 여러 개의 조건을 동시에 만족시켜야 할 때는 조건들을 and로 이어준다.
# 2개 이상 일때 (AND)
cond1 = df['할인율'] >= 0.2
cond2 = df['칼로리'] < 400
df[cond1 & cond2]

> 2개 이상 일때 (OR)
# 2개 이상 일때 (OR)
# 할인율 >= 0.2
# 칼로리 < 400
cond1 = df['할인율'] >= 0.2
cond2 = df['칼로리'] < 400
df[cond1 | cond2]

> 문자열 1개 조건
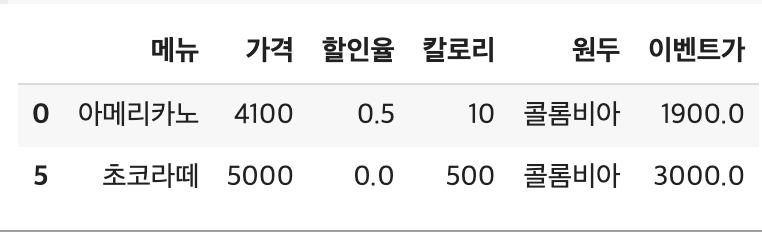
# 문자열 1개 조건
# 원두 == 콜롬비아
cond = df['원두'] == "콜롬비아"
df[cond]
> 문자열과 숫자 조건 (AND)
# 문자열과 숫자 조건 (AND)
# 원두 == 콜롬비아
# 가격 < 4500
cond1 = df['원두'] == "콜롬비아"
cond2 = df['가격'] < 4500
df[cond1 & cond2]

#2 결측치
결측치 확인
# 컬럼별 결측치 확인
df.isnull().sum()

- 위와 같은 결과가 나오는 이유
: df.isnull()까지만 하면 값이 null이면 True를, 아니면 False를 반환하는 데이터프레임이 생성되는데,
여기에 sum()을 하면 각 컬럼별 합산값이 나오므로, True인 경우에만 1씩 더하기 때문이다.

결측값 채우기
- df['col'].fillna('alternative_string') or df['col'].fillna(alternative_number)
: 결측값 셀들을(NaN) 특정 값으로 채우는 api
# '원두' 컬럼의 결측값들을 '코스타리카'로 채우기
df['원두'] = df['원두'].fillna('코스타리카')
df

# '이벤트가'컬럼 결측치는 1900으로 결측치 채움
df['이벤트가'] = df['이벤트가'].fillna(1900)
df

#3. 값 변경
replace로 값 변경하기
> df.replace('before','after') : 첫 번째 인자의 값을 두 번째 인자로 변경
- .replace를 여러번 써도 된다.
- 'before', 'after' 인자값들을 dictionary 형태로 써줘도 된다. 이 때, dictionary 변수를 d 라고 할 때, df.replace(d)의 형식으로 써준다.
# 문자 변경 : 아메리카노 -> 룽고, 녹차 -> 그린티
df.replace('아메리카노', '룽고').replace('녹차','그린티')

d = {'아메리카노':'룽고', '녹차':'그린티'}
df = df.replace(d)
df

# 숫자 변경 : 1900 -> 1500
df = df.replace(1900, 1500)
df

인덱싱/슬라이싱으로 값 변경하기
# loc로 값 변경하기
# 바닐라라떼 원두 -> 과테말라로 변경
df.loc[3, "원두"] = "과테말라"
df

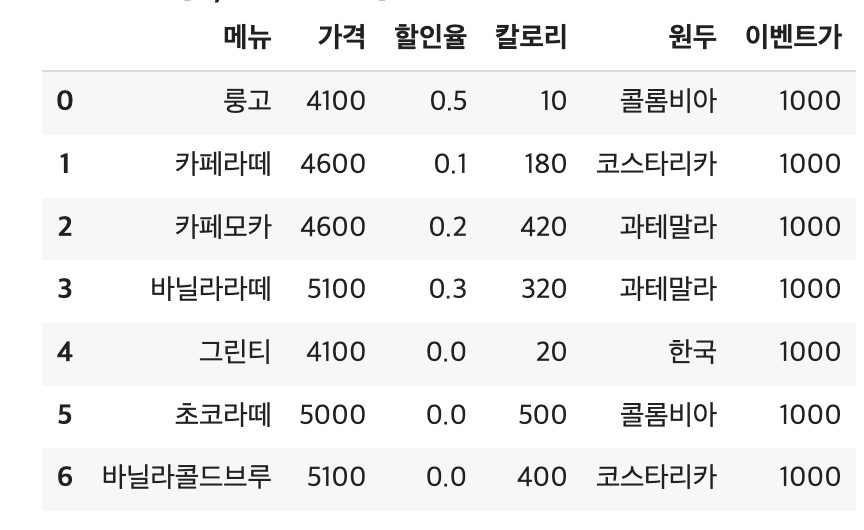
# 이벤트가 전체 1000으로 변경
df.loc[:, '이벤트가'] = 1000
df
#4 내장함수
- 지금까지 살펴봤던 내장함수들 외에, 추가적으로 가장 많이 쓰이는 내장 함수들을 정리한다.
df.count()
- 기본값 (axis = 0) : df.count(), 컬럼별 데이터 개수
- df.count(axis=1) : 행별 데이터 개수
- 결측치는 count에서 제외
# 카운트 (컬럼) #기본값 axis=0
df.count()

# 카운트 (행)
df.count(axis=1)

len(df), df.shape
- len(df) : 데이터의 개수 (데이터프레임의 record 수)
- df.shape : 속성값이므로 소괄호 없이 사용하고, (record의 수, column의 수)를 출력한다. 출력 결과는 튜플 자료형이다.
→ df.shape[0]를 하면 record수가 출력된다.

데이터프레임 기초통계 함수
- df['col'].함수명() : 해당 컬럼의 함수값
- df.함수명() : 데이터프레임의 각 컬럼별 함수 적용값
본 절에서 나열할 기초통계함수는 모두 위와 같이 컬럼을 명시하여 사용할 수도 있고, 데이터프레임 전체적으로 함수를 적용시킬수도 있다.
편의상 한 가지 컬럼에 대해서만 함수를 적용해본다.
기초통계 함수 1 (★)
우선, 아래의 데이터프레임의 '가격' 컬럼에 대해 기초통계 함수를 적용시켜본다.
max = df['가격'].max() # 최대값
min = df['가격'].min() # 최소값
mean = df['가격'].mean() # 평균값
median = df['가격'].median() # 중앙값
sum = df['가격'].sum() # 합계
std = df['가격'].std() # 표준편차
var = df['가격'].var() # 분산
skew = df['가격'].skew() # 왜도 (skewness)
kurt = df['가격'].kurt()
# 첨도 (kurtosis)
print('\'가격\' 컬럼별 기초통계 함수 적용 결과')
print('-------------------------------')
print("최대값 : {:.2f} ".format(max))
print("최소값 : {:.2f} ".format(min))
print("평균값 : {:.2f} ".format(mean))
print("중앙값 : {:.2f} ".format(median))
print("합계 : {:.2f} ".format(sum))
print("표준편차 : {:.2f} ".format(std))
print("분산 : {:.2f} ".format(var))
print("왜도 : {:.2f} ".format(skew))
print("첨도 : {:.2f} ".format(kurt))

(참고)
- 왜도 (skewness) : 왼쪽 긴 꼬리 = 부호 음수
- 첨도 (kurtosis) : 첨도가 0보다 크면 정규분포보다 긴 꼬리를 갖고, 분포가 보다 중앙부분에 덜 집중되게 되므로 중앙부분이 뾰족한 모양을 가지게 된다.
기초통계 함수 2 : 백분위 수
- 백분위수 (단일 컬럼에 적용 또는 df 전체 적용)
: df['col'].quantile(.(하위)백분위수) 또는 df.quantile(.(하위)백분위수)\
- 백분위 수를 포함한 다양한 기초통계값들을 전체적으로 출력 : df['col'].describe() 또는 df.describe()
> 하위 25% 값
# 하위 25% 값
df['가격'].quantile(.25)

(하위 25%값을 추출하는 조건필터로 활용하기)
# 하위 25% 데이터
cond = df['가격'] < df['가격'].quantile(.25)
df[cond]
> 상위 25% 값
# 상위 25% 값
df['가격'].quantile(.75)

(상위 25%값을 추출하는 조건필터로 활용하기)
# 상위 25% 데이터
cond = df['가격'] > df['가격'].quantile(.75)
df[cond]

> 전체적인 기초통계값들 확인하기

기초통계 함수 3 : 최빈값 구하기
- df['col'].mode()[0] : 최빈값 구하기
※ df['col'].mode() 자체는 series 데이터 타입
※ df 전체적으로 적용하면 각 컬럼별 최빈값들이 나열되는 새로운 데이터프레임이 생성된다.

#5 그룹핑
- SQL의 groupby 함수와 정확히 같은 기능을 같고 있으며, EXCEL의 피벗을 생각하면 된다.
- 그룹핑 기준과(~의) 집계 컬럼(~별), 그리고 집계 함수를 사용하여 그룹핑을 할 수 있다.
- 문법 : df.groupby('col1')['col2', 'col3'].function_name()
→ col2와 col3의 col1별 function_name()
→ col2와 col3은 생략도 가능하며, 이 때에는 col1을 제외한 모든 컬럼에 대한 정보가 모두 출력된다.
→ col2, col3 자리에 한 개의 컬럼만 들어가면 Series 형태로 출력이 되는데, 이럴 때는 데이터프레임으로 변환후 사용하면 편리하다.
# 원두 기준, 평균
df.groupby('원두').mean()

# 원두와 할인율 기준, 평균
df.groupby(['원두', '할인율']).mean()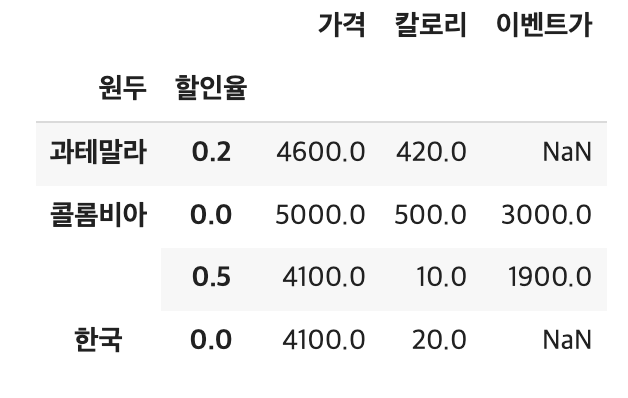
# 원두와 할인율 기준, 가격 평균
df.groupby(['원두', '할인율'])['가격', '칼로리'].mean()
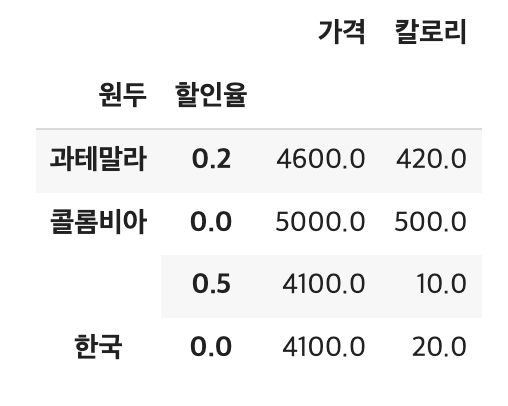
# 원두와 할인율 기준, 가격 평균 -> 데이터 프레임 형태
pd.DataFrame(df.groupby(['원두', '할인율'])['가격'].mean())
- ['가격'] 컬럼 하나이므로 Series 형태로 출력이 되어 데이터프레임으로 변환
# 1개 인덱스 형태로 리셋
df.groupby(['원두', '할인율']).mean().reset_index()
- 보통 분석을 할 때, 데이터프레임에 인덱스가 record마다 있는 것이 편하므로 그룹핑된 데이터프레임에 reset_index()를 적용시킨다. 이렇게 하면 추후 iloc/loc 등의 데이터 조작이 편리해진다.
# 6 Apply 함수 활용 새로운 컬럼 생성 (★)
- Apply함수는 Feature 엔지니어링 시 새로운 컬럼 많을 때 많이 활용되는 함수로, DataFrame과 Series 두 개 타입에 모두 적용 가능

# apply 예시
def cal(x):
if x >= 300:
return "No"
else:
return "Yes"
df['칼로리'].apply(cal)

# apply 적용해서 새로운 컬럼 생성 (칼로리 컬럼 활용)
df['먹어도될까요'] = df['칼로리'].apply(cal)
df

- 이처럼 df['col'].apply(function)을 적용하면 col의 모든 셀마다 function이 작동한다. 여기서는 각각의 셀들이 cal 함수의 x input되어 새로운 값('Yes' or 'No')을 반환한다.
apply with lambda
lambda는 간단한 function을 손쉽게 사용하기 좋으며, 다소 길면 function으로 만드는 것이 좋음. 이유는 가독성이 좋기 때문.
람다 함수는 아래와 같은 형태로 정의됨
lambda 인자 : 표현식
바로 위에서 def로 정의된 cal 함수를 아래와 같이 lambda 함수로 간략하게 표현할 수 있음
df['칼로리'].apply(lambda x : "No" if x>=300 else "Yes")
물론, 아래와 같이 함수를 별도의 변수로 표현할 수도 있음
cal = lambda x : "No" if x>=300 else "Yes"
df['칼로리'].apply(cal)
# Reference
- https://pandas.pydata.org/docs/user_guide/
- https://blog.naver.com/s2ak74/220616766539
'데이터 분석 > Pandas' 카테고리의 다른 글
| [Pandas 핵심] 6. 시계열데이터 다루기 (Datetime, Timedelta) (0) | 2023.11.08 |
|---|---|
| [Pandas 핵심] 4. 인덱싱/슬라이싱, 정렬 (2) | 2023.10.22 |
| [Pandas 핵심] 3. 데이터프레임 변경/삭제, csv로 저장하기/불러오기 (2) | 2023.10.20 |
| [Pandas 핵심] 2. 탐색적 데이터 분석 (EDA) 시 활용 함수들 (0) | 2023.10.17 |
| [Pandas 핵심] 1. DataFrame과 Series (0) | 2023.10.17 |



