본 게시물은 코드잇의 웹자동화 시작하기라는 강의를 듣고 정리한 게시물임을 알려드립니다.
1. 서버와 클라이언트
- 클라이언트 : 서비스를 제공받는 쪽
- 서버 : 서비스를 제공해주는 쪽
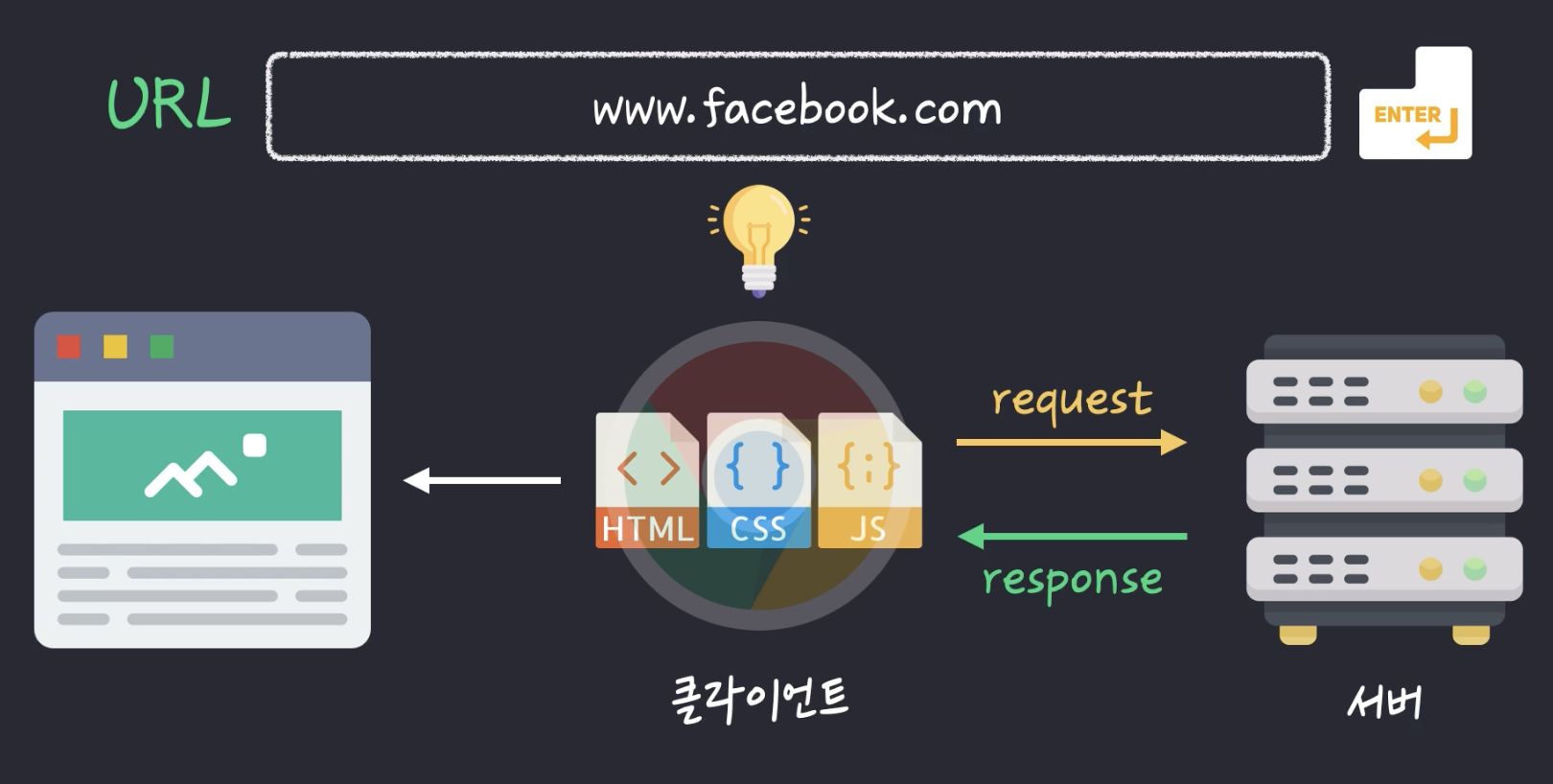
- 크롬 주소창에 www.facebook.com을 치면(requests를 보내면) 서버는 페이스북이, 클라이언트는 브라우저인 크롬이 되는것.
- 즉, 페이스북 서버가 요청에 따라 크롬 클라이언트에 html 코드와 js, css 코드를 보내줌
- 이 응답에 따라 크롬 클라이언트가 적절한 웹 페이지를 보여주는 것
2. 필요한 라이브러리 설치하기
웹크롤링 실습 프로젝트 생성
이름 = web_automation
파일 생성
이름 = main.py
파이썬 라이브러리 'requests' 설치
스탠다드 모듈 : os, datetime, shutil 등 설치 안해도 사용 가능, 외부 라이브러리 : 설치 필요
requests 라이브러리 설치해서 사용할 예정
- 터미널에 아래 명령어 입력
pip install requests
※ 제거를 하고 싶으면 uninstall
3. 파이썬으로 요청 보내기

import requests
response = requests.get("https://google.com") # requests를 보내고 싶은 사이트 이름
print(response)
- response 200이라고 뜨면 성공한것이며, 여기서 말하는 200은 상태코드로, 성공 시 200 / 실패하면 500
import requests
response = requests.get("https://google.com") # requests를 보내고 싶은 사이트 이름
print(response.text)
- 출력 결과를 확인해보면 아래와 같이 구글사이트의 html 코드를 확인할 수 있고, 자세히 보면 html 태그들이 보임
[실습] 4. TV 시청률 데이터 가져오기 1
Q. 티비랭킹닷컴에서 시청률 정보를 공개했습니다. 재빠르게 데이터를 모아서 데이터 분석에 활용해 보려고 하는데요. 티비랭킹닷컴의 HTML 코드를 rating_page에 저장해 주세요.
A.
import requests
response = requests.get("https://workey.codeit.kr/ratings/index")
print(response.text)
5. 웹사이트 주소 이해하기
보통 여러 웹사이트를 활용하는 경우가 많아서 우선 url에 대한 이해부터 필요함
url 구성
웹서버와 소통하는 방식(가장 기본적인 방식 + 보안성 강화 = https://) / 도메인 / 경로
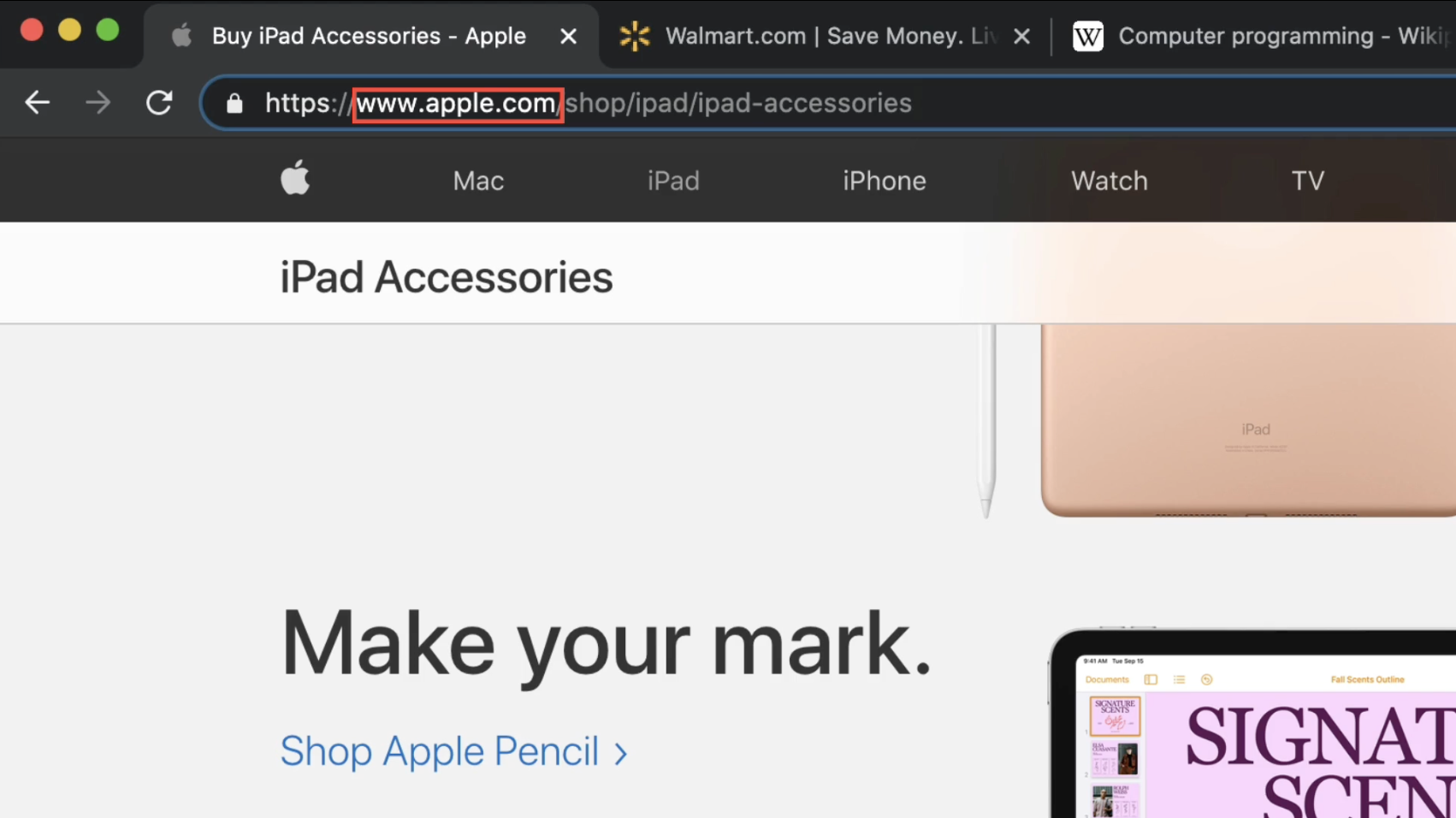
- 경우에 따라서 경로 중에 순서를 바꿔도 되는 경우도 있고, 같은 페이지라도 표출 페이지의 위치를 결정해주는 기호(#)로 url 구성도 가능
6. 여러 웹사이트 한꺼번에 가져오기
원본 url :
https://workey.codeit.kr/ratings/index
티비랭킹닷컴
가구시청률 TOP 10 (분석기준: National, 유료플랫폼 가입 기구, 단위:%) 순위 채널 프로그램 시청률 1 KBS2 주말연속극(수상한삼형제) 33.4 2 KBS1 일일연속극(다함께차차차) 33.1 3 KBS2 해피선데이 27.1 4 MBC
workey.codeit.kr
쿼리 파라미터 조정을 통해 여러 페이지 탐색 가능 (2010년 1월 조회) :
https://workey.codeit.kr/ratings/index?year=2010&month=1&weekIndex=2
실습 : 2010년 1월에 해당하는 웹페이지들의 (1~5주차)주소 리스트업하기
import requests
rating_pages = []
# https://https://workey.codeit.kr/ratings/index?year=2010&month=1&weekIndex=0
for i in range(5):
url = "https://workey.codeit.kr/ratings/index?year=2010&month=1&weekIndex={}".format(i)
response = requests.get(url)
rating_page = response.text
rating_pages.append(rating_page)
print(len(rating_pages))
print(rating_pages[0])7. TV 시청률 데이터 가져오기 2
Q. 티비랭킹닷컴 사이트에서 처음 3년(2010~2012)간의 데이터를 가져와 주세요. 웹사이트 주소의 구조를 활용해서, 모든 페이지의 HTML 코드를 rating_pages에 저장해 주세요. 2010년 1월부터 2012년 12월까지 모든 달에 대해, 1주 차~5주 차 페이지를 순서대로 리스트에 넣어 주시면 됩니다.
이전 레슨에서 봤듯이, 5주 차가 없는 달은 데이터가 없는 페이지가 나오는데요. 그런 페이지들도 리스트에 넣어 주세요. 코드를 실행하는 데 다소 시간이 걸릴 수 있습니다.
A.
import requests
# 여기에 코드를 작성하세요
rating_pages = []
years = [2010, 2011, 2012]
for i in years :
for j in range(1,13) :
for k in range(5) :
url = "https://workey.codeit.kr/ratings/index?year={}&month={}&weekIndex={}".format(i,j,k)
response = requests.get(url)
rating_page = response.text
rating_pages.append(rating_page)
# 테스트 코드
print(len(rating_pages)) # 가져온 총 페이지 수
print(rating_pages[0]) # 첫 번째 페이지의 HTML 코드
range() 함수
- range(b) : 0에서 b-1
- range(a, b) : a에서 b-1
Reference
'데이터 엔지니어링 > 웹크롤링 - [인강] 코드잇, 상시' 카테고리의 다른 글
| [코드잇-웹자동화 시작하기] 3. 웹 스타일링 (2) | 2024.09.14 |
|---|---|
| [코드잇-웹자동화 시작하기] 1. 웹의 기본 요소 (2) | 2024.08.31 |

